
เทคโนโลยีการประมวลผลภาพด้วยคอมพิวเตอร์ (Computer Vision) เป็นหนึ่งในแขนงของปัญญาประดิษฐ์ที่มีความซับซ้อนและก้าวหน้าอย่างรวดเร็ว โดยมุ่งเน้นไปที่การทำให้คอมพิวเตอร์สามารถแยกแยะ ทำความเข้าใจ และประมวลผลภาพหรือวิดีโอในลักษณะที่ใกล้เคียงหรือเหนือกว่าความสามารถของมนุษย์ กระบวนการนี้อาศัยแบบจำลองเชิงคณิตศาสตร์ที่สามารถตรวจจับรูปแบบ (Pattern Recognition) และสร้างการอนุมาน (Inference) เกี่ยวกับวัตถุหรือฉากในภาพที่ได้รับ
ในขณะที่การมองเห็นของมนุษย์พัฒนาไปตามกระบวนการวิวัฒนาการที่ใช้เวลาหลายล้านปี การพัฒนา Computer Vision อาศัยการเรียนรู้เชิงลึก (Deep Learning) และการใช้เครือข่ายประสาทเทียมแบบคอนโวลูชัน (Convolutional Neural Networks - CNNs) เพื่อให้สามารถระบุและจำแนกวัตถุในภาพได้อย่างแม่นยำ กระบวนการเหล่านี้ได้รับการปรับปรุงอย่างต่อเนื่องโดยอาศัยชุดข้อมูลขนาดใหญ่และพลังการประมวลผลที่เพิ่มขึ้นของฮาร์ดแวร์คอมพิวเตอร์ยุคใหม่

ภาพที่ 1 เปรียบเทียบระหว่าง Pixels และภาพ Grayscale ในแต่ละตำแหน่งเดียวกัน
( ที่มา: https://setosa.io/ev/image-kernels/ )
คอมพิวเตอร์ "เห็น" อย่างไร?
คอมพิวเตอร์ไม่ได้รับรู้ภาพในลักษณะเดียวกับที่ดวงตามนุษย์ทำงาน แต่แทนที่จะเป็นการแปลงคลื่นแสงเป็นสัญญาณประสาท คอมพิวเตอร์จะรับข้อมูลภาพเป็นเมทริกซ์ของค่าพิกเซลซึ่งแทนค่าสีและความเข้มของแสงในแต่ละจุดในภาพ โดยทั่วไป ภาพดิจิทัลประกอบด้วยองค์ประกอบพื้นฐานดังนี้:
ภาพขาวดำ (Grayscale Images): แต่ละพิกเซลมีค่าความเข้มที่อยู่ในช่วง 0-255 โดยค่าต่ำสุด (0) หมายถึงสีดำ และค่าสูงสุด (255) หมายถึงสีขาว
ภาพสี (RGB Images): แทนด้วยช่องสี (Color Channels) ได้แก่ แดง (Red), เขียว (Green) และน้ำเงิน (Blue) โดยการรวมกันของทั้งสามค่าสามารถสร้างสีได้หลายล้านเฉด
ภาพแบบหลายสเปกตรัม (Multispectral and Hyperspectral Images): ใช้ในการวิเคราะห์ทางวิทยาศาสตร์ เช่น การถ่ายภาพทางการแพทย์และภาพถ่ายดาวเทียมที่สามารถจับรายละเอียดที่มองไม่เห็นด้วยตาเปล่า
กระบวนการประมวลผลภาพ
เพื่อให้คอมพิวเตอร์สามารถ "เข้าใจ" ข้อมูลที่ได้รับ กระบวนการ Computer Vision ประกอบด้วยขั้นตอนหลักหลายประการ ได้แก่:
1. การประมวลผลล่วงหน้า (Preprocessing)
การลดสัญญาณรบกวน (Noise Reduction) ด้วยเทคนิคต่างๆ เช่น Gaussian Filtering หรือ Median Filtering
การเพิ่มความคมชัดของภาพผ่านเทคนิคต่างๆ เช่น Histogram Equalization
การปรับแต่งขนาดและความละเอียดของภาพเพื่อให้เหมาะสมกับโมเดลที่ใช้ในการประมวลผล
2. การดึงคุณลักษณะ (Feature Extraction)
การใช้ตัวตรวจจับขอบ (Edge Detection) เช่น Sobel, Canny หรือ Laplacian Filter
การใช้เทคนิค Histogram of Oriented Gradients (HOG) หรือ Scale-Invariant Feature Transform (SIFT) เพื่อระบุลักษณะเฉพาะของวัตถุ
3. การจำแนกประเภทและรู้จำวัตถุ (Object Detection and Recognition)
การใช้ Convolutional Neural Networks (CNNs) เช่น ResNet, VGG หรือ EfficientNet ในการแยกประเภทของวัตถุ
อัลกอริธึมที่ได้รับความนิยม เช่น You Only Look Once (YOLO) และ Faster R-CNN ที่สามารถตรวจจับและจำแนกวัตถุในภาพได้อย่างรวดเร็วและแม่นยำ
การใช้ Generative Adversarial Networks (GANs) เพื่อสร้างและปรับแต่งภาพที่มีความสมจริง
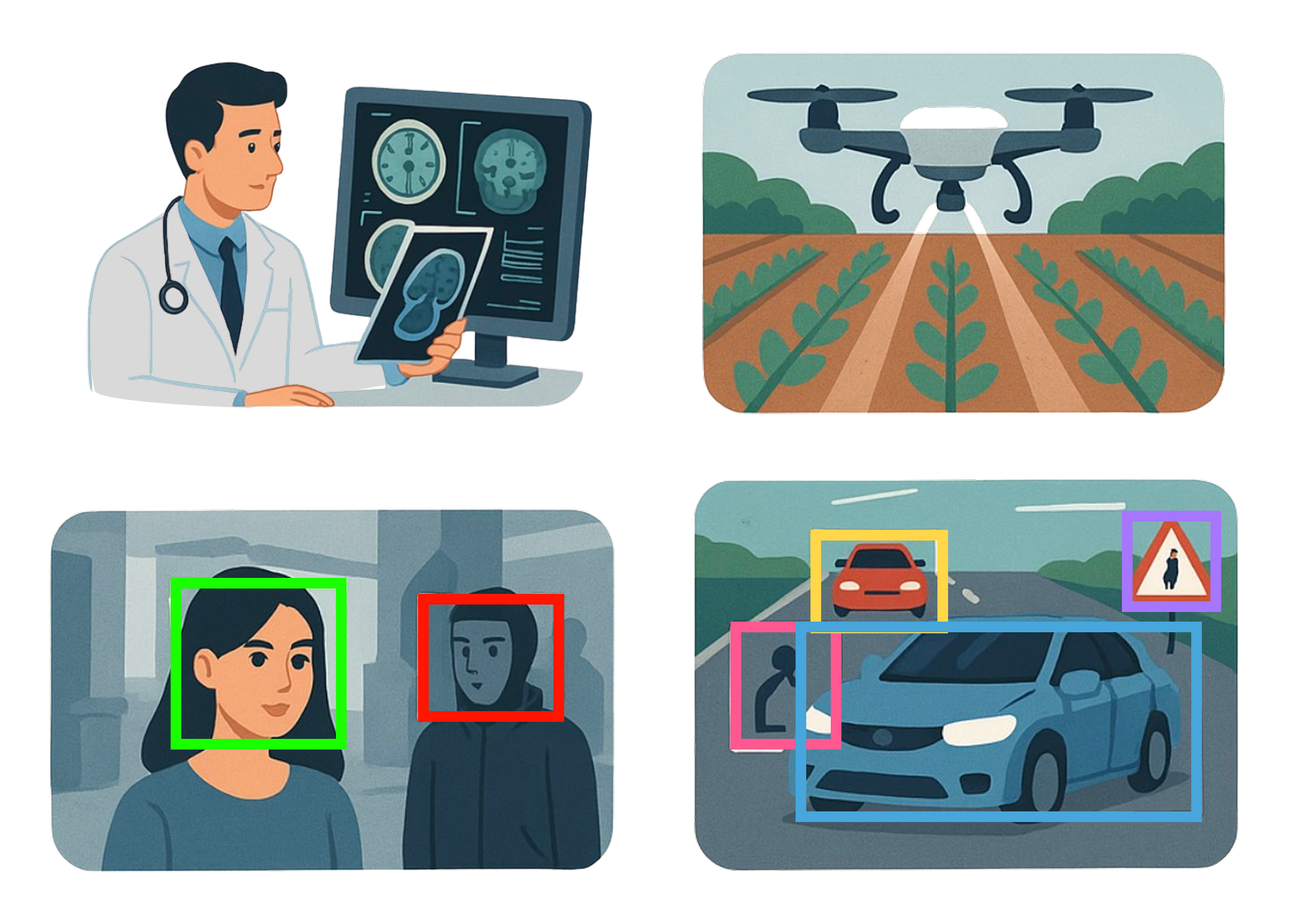
ภาพที่ 2 การประยุกต์ใช้ Computer Vision
เทคโนโลยีและการประยุกต์ใช้
Computer Vision เป็นเทคโนโลยีที่มีบทบาทสำคัญในหลายอุตสาหกรรม โดยช่วยให้คอมพิวเตอร์สามารถวิเคราะห์และตีความข้อมูลจากภาพและวิดีโอได้อย่างแม่นยำ ด้วยความก้าวหน้าของ Machine Learning และ Deep Learning การประยุกต์ใช้ Computer Vision ได้ขยายไปยังหลายสาขา ซึ่งส่งผลกระทบต่ออุตสาหกรรมหลักๆ ดังนี้
1. การแพทย์
Computer Vision ถูกนำมาใช้ในการช่วยวินิจฉัยโรคและสนับสนุนการตัดสินใจของแพทย์ผ่านการวิเคราะห์ภาพถ่ายทางการแพทย์ เช่น:
การวิเคราะห์ภาพเอกซเรย์, CT Scan และ MRI: ช่วยตรวจจับโรค เช่น มะเร็ง โรคหลอดเลือดสมอง และภาวะผิดปกติของอวัยวะภายใน
การตรวจสอบเซลล์มะเร็งและพยาธิสภาพในภาพจุลทรรศน์: ระบบสามารถวิเคราะห์ตัวอย่างเนื้อเยื่อเพื่อช่วยแพทย์ในการวินิจฉัยโรคได้รวดเร็วและแม่นยำขึ้น
หุ่นยนต์ช่วยผ่าตัด: หุ่นยนต์ที่ใช้ Computer Vision สามารถช่วยศัลยแพทย์ระบุตำแหน่งและโครงสร้างทางกายวิภาคในระหว่างการผ่าตัด
2. ยานยนต์ไร้คนขับ
หนึ่งในเทคโนโลยีที่มีการพัฒนามากที่สุดในปัจจุบันคือ Autonomous Vehicles หรือ ยานยนต์ไร้คนขับ ซึ่งต้องอาศัย Computer Vision เพื่อให้สามารถรับรู้สภาพแวดล้อมรอบตัวได้อย่างแม่นยำ เช่น:
การตรวจจับวัตถุ: ระบบสามารถระบุรถยนต์ คนนั่ง จักรยาน และสิ่งกีดขวางบนถนนได้
การอ่านป้ายจราจร: ใช้ Optical Character Recognition (OCR) และ Object Detection ในการระบุป้ายจราจรและป้ายบอกทาง
การตรวจจับช่องทางจราจร: ใช้ Line Detection และ Semantic Segmentation ในการวิเคราะห์เส้นถนนและปรับเส้นทางของรถ
Computer Vision ในรถยนต์ไร้คนขับยังทำงานร่วมกับเซ็นเซอร์ต่างๆ เช่น LiDAR และ Radar เพื่อให้การขับขี่มีความปลอดภัยมากขึ้น
3. ความปลอดภัยและการเฝ้าระวัง
เทคโนโลยีด้าน Computer Vision ถูกนำมาใช้ในการเพิ่มความปลอดภัยและการตรวจสอบพฤติกรรมในสถานที่สาธารณะ เช่น:
ระบบจดจำใบหน้า (Facial Recognition): ใช้ในสนามบิน สถานีขนส่ง และสถานที่สำคัญต่างๆ เพื่อช่วยยืนยันตัวบุคคลและป้องกันภัยคุกคาม
การตรวจจับพฤติกรรมที่น่าสงสัย: ระบบสามารถตรวจจับพฤติกรรมที่ผิดปกติ เช่น การเคลื่อนไหวที่รวดเร็วผิดปกติ หรือท่าทางที่สื่อถึงการทำร้ายผู้อื่น
การวิเคราะห์ภาพจากกล้องวงจรปิด (CCTV Analytics): ใช้เพื่อตรวจจับการบุกรุก หรือเหตุการณ์ที่อาจนำไปสู่ความเสี่ยง เช่น ไฟไหม้หรือเหตุอาชญากรรม
4. เกษตรกรรมอัจฉริยะ (Smart Agriculture)
Computer Vision ช่วยปรับปรุงกระบวนการเพาะปลูกและดูแลพืชผ่านการใช้โดรนและระบบอัตโนมัติ เช่น:
การใช้โดรนตรวจสอบพืชและสภาพดิน: โดรนติดตั้งกล้องที่สามารถวิเคราะห์สุขภาพของพืช ตรวจหาความชื้นของดิน และตรวจจับการแพร่ระบาดของโรคในไร่
การจำแนกชนิดของพืชและวัชพืช: ใช้ AI เพื่อแยกแยะพืชที่ต้องการปลูกออกจากวัชพืช ซึ่งช่วยลดการใช้สารกำจัดศัตรูพืช
การเก็บเกี่ยวอัตโนมัติ: หุ่นยนต์เก็บเกี่ยวที่ใช้ Computer Vision สามารถวิเคราะห์ความสุกของผลไม้หรือพืชผลทางการเกษตรก่อนทำการเก็บเกี่ยว
ความท้าทายและแนวโน้มในอนาคต
แม้ว่า Computer Vision จะพัฒนาไปอย่างรวดเร็ว แต่ยังมีความท้าทายสำคัญที่ต้องเผชิญ ได้แก่ ความแม่นยำที่ขึ้นอยู่กับข้อมูลฝึกสอน ซึ่งต้องการชุดข้อมูลขนาดใหญ่และครอบคลุมทุกสถานการณ์ ความต้องการทรัพยากรสูง เนื่องจากโมเดล Deep Learning ต้องใช้ฮาร์ดแวร์ที่มีสมรรถนะสูง และ ปัญหาด้านจริยธรรม โดยเฉพาะในระบบจดจำใบหน้า ที่อาจละเมิดความเป็นส่วนตัวและสิทธิพลเมือง
แนวโน้มในอนาคตมุ่งไปสู่ การพัฒนาโมเดลที่ใช้ข้อมูลน้อยลง (Few-shot Learning), การประมวลผลที่มีประสิทธิภาพสูงขึ้น, และ การกำกับดูแลด้านจริยธรรม เพื่อให้การใช้ Computer Vision มีความโปร่งใสและเป็นธรรมมากขึ้น
References
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press.
Szeliski, R. (2022). Computer Vision: Algorithms and Applications. Springer.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-444.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25, 1097-1105.
Redmon, J., & Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767.


