
ในยุคที่เทคโนโลยีปัญญาประดิษฐ์ (AI) ก้าวล้ำอย่างต่อเนื่อง แนวคิดที่ว่าคอมพิวเตอร์สามารถจดจำและแยกแยะใบหน้าของมนุษย์ได้อย่างแม่นยำไม่ใช่เรื่องไกลตัวอีกต่อไป เบื้องหลังของความสามารถนี้ไม่ใช่เวทมนตร์ แต่คือโครงสร้างทางคณิตศาสตร์ที่เรียกว่า "เวกเตอร์" หรือกระบวนการฝังตัวข้อมูล (Embedding) ซึ่งแปลงลักษณะเฉพาะของใบหน้าให้กลายเป็นชุดตัวเลขหลายมิติ สามารถนำมาเปรียบเทียบและประมวลผลได้
มนุษย์จดจำบุคคลผ่านปัจจัยทางสังคม เช่น โครงหน้า น้ำเสียง หรือพฤติกรรม แต่คอมพิวเตอร์อาศัยการแปลงภาพใบหน้าให้เป็นเวกเตอร์ตัวเลขที่แทน "อัตลักษณ์" ทางเรขาคณิตเฉพาะของแต่ละคน เวกเตอร์นี้จึงทำหน้าที่เหมือนลายพิมพ์ดีเอ็นเอเชิงคณิตศาสตร์ที่ไม่ซ้ำกัน
Embedding: จาก Machine Learning ดั้งเดิมสู่ Deep Learning
แนวคิดเรื่อง embedding เริ่มต้นจากยุค Machine Learning แบบดั้งเดิม ก่อนที่ Deep Learning จะเข้ามามีบทบาท เช่น เทคนิคอย่าง TF-IDF ซึ่งคำนวณความสำคัญของคำตามความถี่ในเอกสารหนึ่ง เทียบกับเอกสารทั้งหมดในระบบ, Bag-of-Words ที่แปลงข้อความให้กลายเป็นเวกเตอร์ของการนับจำนวนคำแบบไม่สนลำดับหรือบริบท, ไปจนถึง Word2Vec ซึ่งถือเป็นจุดเปลี่ยนสำคัญที่ทำให้ Embedding เริ่มเข้าใจ "บริบท" ของคำได้ โดยใช้โครงข่ายประสาทเทียมแบบ shallow neural network เพื่อเรียนรู้ความสัมพันธ์ระหว่างคำในประโยค และสร้างเวกเตอร์ที่สามารถสะท้อนความหมายโดยนัยได้ เช่น คำว่า “king” และ “queen” จะมีเวกเตอร์ที่สัมพันธ์กันทางคณิตศาสตร์ การพัฒนา embedding ในยุคนี้แม้จะยังไม่ได้ลึกซึ้งเท่า BERT หรือโมเดลขนาดใหญ่ในยุคปัจจุบัน แต่ก็ปูรากฐานให้กับการแปลงข้อมูลที่มีความหมายซับซ้อนให้กลายเป็นเวกเตอร์หลายมิติ ซึ่งเป็นหัวใจสำคัญของการประมวลผลข้อมูลด้วย AI ทุกรูปแบบ
ในงานด้านการประมวลผลภาพ เทคนิคการฝังเวกเตอร์ เริ่มต้นจากการใช้วิธีการออกแบบฟีเจอร์ด้วยมือ เช่น HOG (Histogram of Oriented Gradients) ซึ่งตรวจจับขอบและทิศทางของภาพ, SIFT (Scale-Invariant Feature Transform) ที่เน้นจุดเด่นที่ไม่แปรเปลี่ยนแม้ภาพจะมีการหมุนหรือปรับขนาด, และ LBP (Local Binary Pattern) ซึ่งวิเคราะห์พื้นผิวใบหน้าด้วยรูปแบบไบนารีเฉพาะ อย่างไรก็ตาม เทคนิคเหล่านี้มีข้อจำกัดในแง่ของความยืดหยุ่น การต้านทานต่อการเปลี่ยนแปลงของภาพ (เช่น แสง มุมกล้อง) และประสิทธิภาพในงานจดจำใบหน้าที่ซับซ้อน
เมื่อเข้าสู่ยุคของ Deep Learning การมาถึงของ Convolutional Neural Networks (CNNs) ได้เปลี่ยนแนวทางโดยสิ้นเชิง จากการพึ่งพาฟีเจอร์ที่ออกแบบโดยมนุษย์ มาเป็นการเรียนรู้ฟีเจอร์โดยตรงจากข้อมูลภาพจำนวนมาก ทำให้โมเดลสามารถดึงคุณลักษณะเฉพาะตัวของใบหน้าได้ลึกและแม่นยำมากขึ้น โมเดลฝังเวกเตอร์ใบหน้าระดับสูง เช่น FaceNet, ArcFace และ Glint360k จึงถูกพัฒนาเพื่อสร้างเวกเตอร์ที่สะท้อนเอกลักษณ์ของบุคคลในเชิงคณิตศาสตร์ โดยเวกเตอร์เหล่านี้สามารถนำไปใช้เปรียบเทียบ ระบุ หรือจดจำบุคคลได้ทันที โดยไม่ต้องพึ่งพาวิธีการแยกแยะแบบดั้งเดิมอีกต่อไป
เวกเตอร์ใบหน้าคืออะไร และสร้างขึ้นอย่างไร?

ภาพที่ 1 กระบวนการสร้าง Face Embedding ด้วย Convolutional Neural Networks
หลังจากระบบตรวจจับใบหน้า (Face Detection) ตรวจพบตำแหน่งใบหน้าภายในภาพ จะต้องทำการปรับตำแหน่งใบหน้าให้ได้สัดส่วนและมุมที่เหมาะสม (Face Alignment) เช่น หมุนภาพให้ดวงตาทั้งสองข้างอยู่ในแนวระนาบเดียวกัน หรือจัดตำแหน่งตามจุด Landmark บนใบหน้า เพื่อให้มั่นใจว่าใบหน้าทุกภาพจะถูกแปลงในบริบทเดียวกัน ซึ่งเป็นขั้นตอนสำคัญต่อความแม่นยำของระบบจดจำใบหน้า
[0.0041, -0.132, 0.254, ..., -0.0867] # รูปแบบของ Face Embeddingเมื่อจัดตำแหน่งเสร็จแล้ว ภาพใบหน้าจะถูกส่งต่อไปยังโมเดลจำแนกใบหน้า (Face Recognition Model) ที่ผ่านการฝึกมาแล้ว เช่น ArcFace, FaceNet หรือ Glint360k โมเดลเหล่านี้มักใช้โครงข่ายประสาทเทียมแบบ Convolutional Neural Networks (CNN) เพื่อเรียนรู้ลักษณะเฉพาะของใบหน้า แล้วแปลงข้อมูลภาพให้กลายเป็นเวกเตอร์หลายมิติ (High-Dimensional Embedding Vector) ซึ่งเวกเตอร์นี้อาจมีความยาวตั้งแต่ 128, 256 หรือ 512 มิติ ขึ้นกับโครงสร้างของโมเดลที่ใช้ เวกเตอร์นี้สามารถใช้คำนวณเพื่อหาความใกล้เคียงกับบุคคลอื่น ๆ ได้ โดยไม่ต้องใช้ภาพใบหน้าจริง
ค้นหาใบหน้าด้วยการวัดระยะทางในเวกเตอร์สเปซ
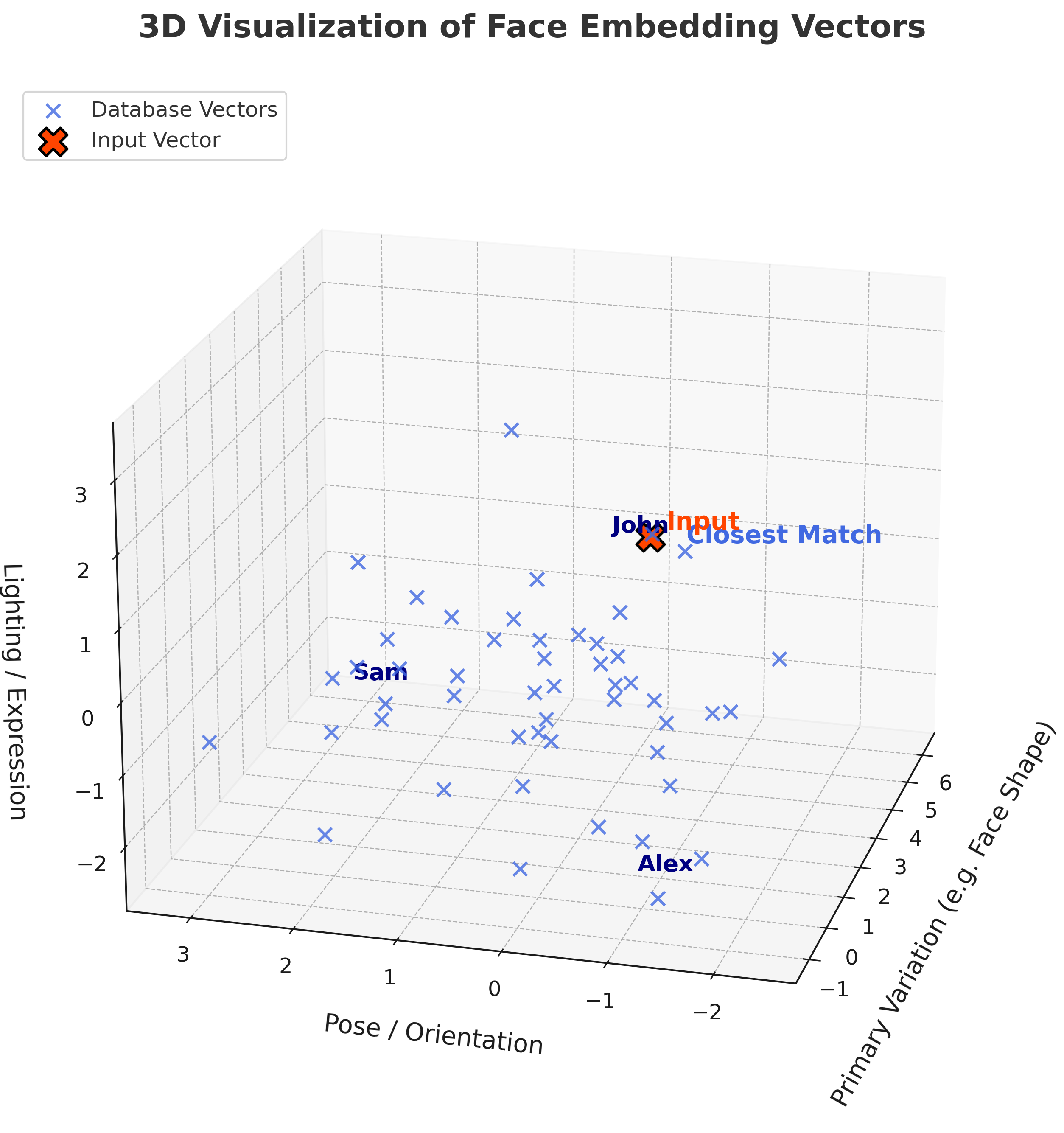
ภาพที่ 2 เวกเตอร์ใบหน้าบนเวกเตอร์สเปซสามมิติหลังลดมิติด้วย PCA จุดสีแดงคือเวกเตอร์จากใบหน้าที่ต้องการตรวจสอบ ส่วนจุดสีน้ำเงินแทนเวกเตอร์ของบุคคลในฐานข้อมูล ตำแหน่งที่ใกล้กันสะท้อนระดับความคล้ายคลึงของใบหน้าในเชิงคณิตศาสตร์
ระบบจดจำใบหน้าแบบเวกเตอร์ทำงานโดยแปลงภาพใบหน้าให้เป็นเวกเตอร์หลายมิติ (Face Embedding) ซึ่งเป็นตัวแทนทางคณิตศาสตร์ของลักษณะใบหน้า จากนั้นระบบจะค้นหาใบหน้าด้วยการเปรียบเทียบเวกเตอร์นี้กับเวกเตอร์หน้าอื่น ๆ ที่ถูกเก็บไว้ในฐานข้อมูล โดยใช้ระยะทางเชิงตัวเลข เช่น Euclidean Distance หรือ Cosine Similarity หากค่าระยะห่างอยู่ในช่วงที่กำหนด (เช่น < 0.5) จะถือว่าเป็นบุคคลเดียวกัน วิธีนี้ช่วยให้สามารถระบุตัวบุคคลได้โดยไม่ต้องเก็บภาพจริง ลดความเสี่ยงด้านความเป็นส่วนตัว
เพื่อให้การเปรียบเทียบแม่นยำยิ่งขึ้น โมเดลจดจำใบหน้าสมัยใหม่มักฝึกด้วยเทคนิคเฉพาะ เช่น Triplet Loss หรือ Contrastive Loss ซึ่งออกแบบมาเพื่อปรับโครงสร้างของ Embedding Space ให้เวกเตอร์ของใบหน้าบุคคลเดียวกันอยู่ใกล้กัน และของคนละคนอยู่ห่างกันอย่างชัดเจน นอกจากนี้ โมเดลระดับสูงเช่น ArcFace ยังใช้แนวทางที่เรียกว่า Additive Angular Margin Loss ซึ่งเป็นการเพิ่มระยะห่างเชิงมุมระหว่างคลาสต่าง ๆ เพื่อให้เกิด Decision Boundary ที่ชัดเจนยิ่งขึ้น เทคนิคเหล่านี้ช่วยเพิ่มประสิทธิภาพของการรู้จำ แม้ในกรณีที่ใบหน้ามีความคล้ายกัน หรืออยู่ภายใต้แสงและมุมที่แตกต่างกันอย่างมาก
ตัวอย่างการใช้งานจริง
ระบบลงเวลาทำงาน: กล้องสามารถยืนยันตัวตนของคุณจากเวกเตอร์ใบหน้าโดยไม่ต้องใช้บัตรหรือสแกนนิ้ว
ระบบควบคุมการเข้าถึง (Access Control): เปรียบเทียบเวกเตอร์ใบหน้ากับฐานข้อมูลก่อนอนุญาตให้เข้าพื้นที่สำคัญ
Face Unlock บนโทรศัพท์มือถือ: ยืนยันตัวตนจากใบหน้า แม้มีการเปลี่ยนแปลงเล็กน้อย เช่น แต่งหน้า ใส่แว่น หรือมีแสงต่างกัน
การสืบค้นวิดีโอและภาพถ่าย: ระบบสามารถค้นหาบุคคลจากกล้องวงจรปิดหรือคลิปวิดีโอได้อย่างรวดเร็ว
ข้อพิจารณาด้านความปลอดภัย
แม้เวกเตอร์ใบหน้าไม่สามารถย้อนกลับไปเป็นภาพต้นฉบับได้โดยตรง แต่ก็ถือเป็นข้อมูลชีวภาพที่มีความละเอียดอ่อน หากถูกใช้อย่างไม่เหมาะสม อาจนำไปสู่การละเมิดความเป็นส่วนตัว เช่น การติดตามบุคคลโดยไม่ได้รับความยินยอม
เพื่อความปลอดภัย ควรมีมาตรการ เช่น การเข้ารหัสเวกเตอร์ การจำกัดสิทธิ์เข้าถึง และการกำกับดูแลการใช้งานตามกรอบกฎหมายหรือจริยธรรม
Reference
Schroff, F., Kalenichenko, D., & Philbin, J. (2015). FaceNet: A unified embedding for face recognition and clustering. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 815–823.
Deng, J., Guo, J., Xue, N., & Zafeiriou, S. (2020). ArcFace: Additive Angular Margin Loss for Deep Face Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10), 5745–5760.


