
เมื่อพูดถึงการมองเห็นของคอมพิวเตอร์ (Computer Vision) หลายคนอาจนึกถึงเทคโนโลยีสแกนใบหน้า รถยนต์ไร้คนขับ หรือปัญญาประดิษฐ์ที่สามารถจดจำและวิเคราะห์ภาพถ่ายได้ แต่เคยสงสัยไหมว่า "ภาพแรก" ที่คอมพิวเตอร์สามารถมองเห็นและประมวลผลได้คืออะไร? การที่เครื่องจักรสามารถมองเห็นและทำความเข้าใจภาพได้ถือเป็นก้าวสำคัญที่พลิกโฉมวงการวิทยาการคอมพิวเตอร์และปัญญาประดิษฐ์ ในบทความนี้เราจะพาคุณย้อนเวลากลับไปดูจุดเริ่มต้นของ Computer Vision และสำรวจว่าภาพแรกที่คอมพิวเตอร์เคยมองเห็นนั้นเป็นอย่างไร
กำเนิดแนวคิดการมองเห็นของคอมพิวเตอร์
แนวคิดเกี่ยวกับการให้คอมพิวเตอร์ "มองเห็น" นั้นเกิดขึ้นในช่วงกลางศตวรรษที่ 20 นักวิทยาศาสตร์เริ่มทดลองสร้างระบบที่สามารถแปลงภาพถ่ายให้เป็นข้อมูลดิจิทัลที่คอมพิวเตอร์สามารถประมวลผลได้ เทคโนโลยีนี้มีพื้นฐานจากการประมวลผลสัญญาณดิจิทัล (Digital Signal Processing) และการวิเคราะห์รูปแบบ (Pattern Recognition) โดยแนวคิดนี้ได้รับแรงบันดาลใจจากระบบการมองเห็นของมนุษย์
ภาพแรกที่คอมพิวเตอร์วิเคราะห์
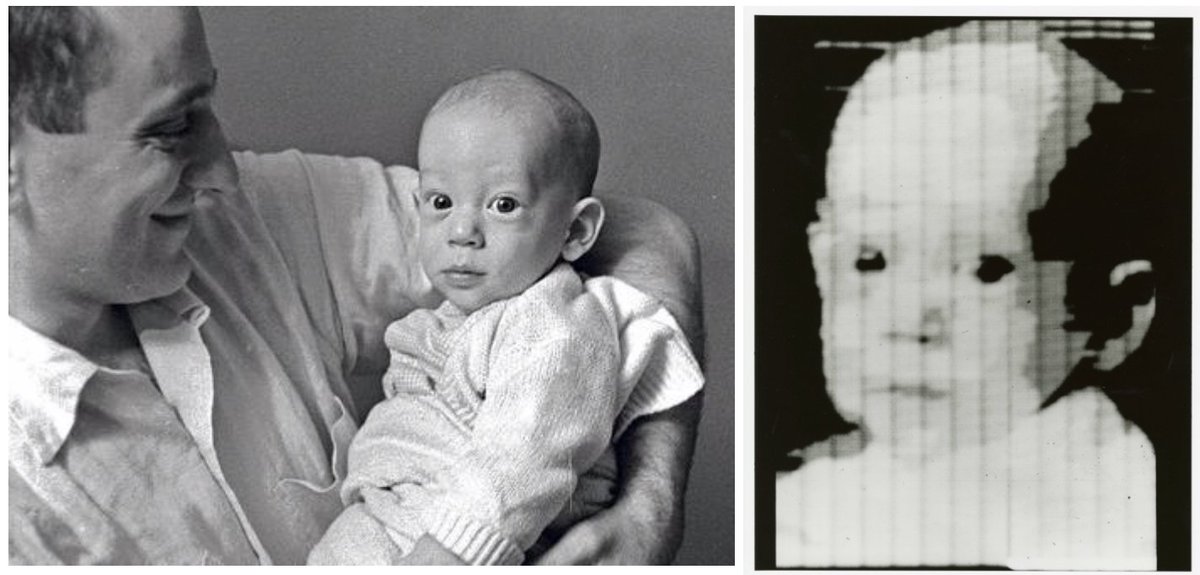
ภาพที่ 1 ภาพแรกที่คอมพิวเตอร์มองเห็น
(ที่มา: https://www.nist.gov/mathematics-statistics/first-digital-image)
ภาพดิจิทัลแรกของโลกถูกสร้างโดย รัสเซล เคิร์ช (Russell Kirsch) ในปี 1957 เป็นภาพขาวดำขนาด 176 x 176 พิกเซล ของลูกชายเขา วอลโด เคิร์ช (Waldo Kirsch) ซึ่งถือเป็นจุดเริ่มต้นของ เทคโนโลยีดิจิทัลอิมเมจ และ การประมวลผลภาพดิจิทัล โดยภาพนี้ถูกสแกนเข้าสู่คอมพิวเตอร์ผ่าน Drum Scanner ที่ National Bureau of Standards (NBS) หรือ NIST ในปัจจุบัน เคิร์ชและทีมงานพัฒนา Binary Encoding เพื่อแปลงภาพเป็นข้อมูลดิจิทัล วางรากฐานให้กับ Computer Vision และเทคนิค Edge Detection ซึ่งนำไปสู่ Pattern Recognition และ AI ในยุคต่อมา
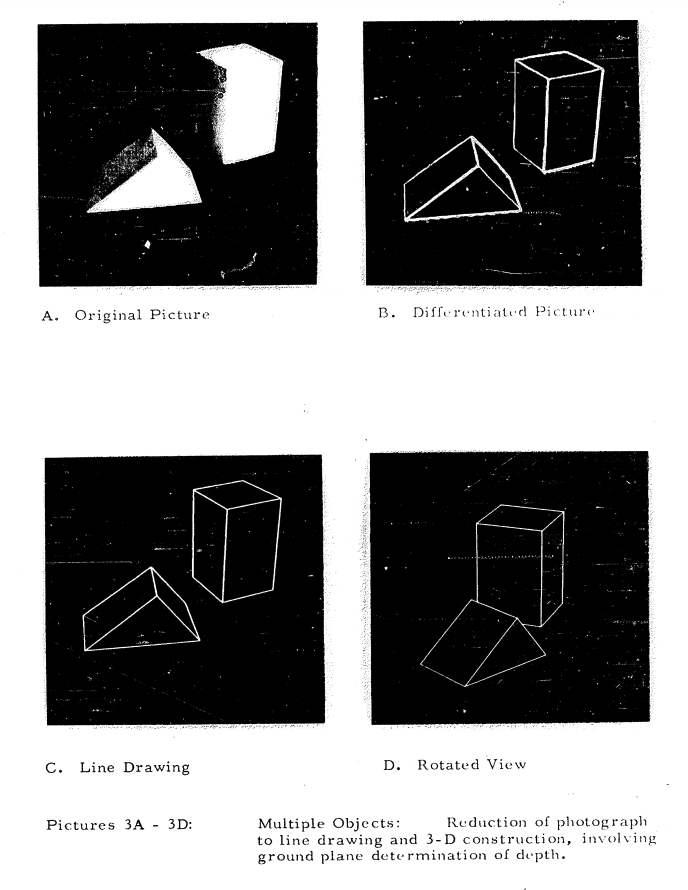
ภาพที่ 2 แบบจำลองสามมิติจากภาพสองมิติ
(ที่มา: Roberts, L. (1963). Machine perception of three-dimensional solids. MIT Press.)
และหนึ่งในตัวอย่างที่โด่งดังที่สุดคือการทดลองของ แลร์รี่ โรเบิร์ตส์ (Larry Roberts) ในปี 1963 ซึ่งเขาใช้ภาพสองมิติของวัตถุเพื่อสร้างแบบจำลองสามมิติ แนวคิดนี้กลายเป็นรากฐานของการพัฒนา Computer Vision ในปัจจุบัน
เทคโนโลยีที่ใช้ในช่วงแรกของ Computer Vision
การประมวลผลภาพในยุคแรกมีข้อจำกัดอย่างมาก เนื่องจากข้อจำกัดของฮาร์ดแวร์และซอฟต์แวร์ คอมพิวเตอร์ในขณะนั้นมีพลังการประมวลผลต่ำ ขนาดใหญ่ และการทำงานยังล่าช้า ส่งผลให้การวิเคราะห์ภาพต้องใช้เวลานาน นอกจากนี้ ระบบยังขาดฐานข้อมูลภาพขนาดใหญ่สำหรับฝึกแบบจำลอง ทำให้เทคนิคด้าน Computer Vision ในยุคนั้นยังอยู่ในขั้นเริ่มต้น
เพื่อแก้ไขข้อจำกัดดังกล่าว นักวิจัยได้ใช้ เทคนิคพื้นฐาน เพื่อช่วยให้คอมพิวเตอร์สามารถตีความและวิเคราะห์ภาพได้ง่ายขึ้น เช่น:
Edge Detection (การตรวจจับขอบภาพ): ใช้ระบุโครงร่างของวัตถุภายในภาพ วิธีการนี้ช่วยให้คอมพิวเตอร์สามารถแยกขอบเขตของวัตถุออกจากพื้นหลัง เช่น การใช้ตัวกรอง Sobel หรือ Canny Edge Detector ในเวลาต่อมา
Binary Image Processing (การประมวลผลภาพแบบไบนารี): ภาพถูกแปลงเป็นขาว-ดำ เพื่อให้คอมพิวเตอร์สามารถประมวลผลได้ง่ายขึ้น เทคนิคนี้ใช้กันอย่างแพร่หลายใน OCR (Optical Character Recognition) และการแยกพื้นหลัง
Pattern Recognition (การวิเคราะห์รูปแบบ): มุ่งเน้นการแยกแยะและระบุวัตถุในภาพ โดยอาศัยคุณสมบัติพื้นฐานของภาพ เช่น รูปร่าง และขนาด ซึ่งต่อมาเป็นรากฐานของเทคนิค Machine Learning ที่พัฒนาขึ้นในภายหลัง
นอกจากนี้ คอมพิวเตอร์ในยุคนั้นสามารถทำงานกับ ภาพขาวดำเท่านั้น ทำให้รายละเอียดของใบหน้าหรือวัตถุยังถูกระบุได้อย่างจำกัด ความแม่นยำในการจำแนกวัตถุยังต่ำเมื่อเทียบกับเทคโนโลยีในปัจจุบัน เนื่องจากยังไม่มีอัลกอริธึมที่ซับซ้อนหรือเครือข่ายประสาทเทียมที่มีประสิทธิภาพสูง
แม้จะมีข้อจำกัดเหล่านี้ แต่แนวคิดและเทคนิคที่พัฒนาขึ้นในช่วงแรกถือเป็นรากฐานสำคัญของ Computer Vision ในปัจจุบัน ซึ่งต่อยอดไปสู่การพัฒนาอัลกอริธึมขั้นสูง เช่น Convolutional Neural Networks (CNNs) และ Deep Learning ที่สามารถทำความเข้าใจภาพได้อย่างแม่นยำมากขึ้น
References
Kirsch, R. (1957). Computers and automation: Digital picture processing. National Bureau of Standards.
Roberts, L. (1963). Machine perception of three-dimensional solids. MIT Press.
Marr, D. (1982). Vision: A Computational Investigation into the Human Representation and Processing of Visual Information. W. H. Freeman.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-444.
Krizhevsky, A., Sutskever, I., & Hinton, G. (2012). ImageNet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
Redmon, J., & Farhadi, A. (2018). YOLOv3: An Incremental Improvement. arXiv preprint arXiv:1804.02767.


