
ทุกวันนี้เทคโนโลยีก้าวไกลอย่างไม่น่าเชื่อ และหนึ่งในเรื่องที่น่าสนใจมากก็คือความสามารถของคอมพิวเตอร์ในการ “มองเห็น” โลกใบนี้ได้เหมือนกับมนุษย์เรานี่แหละ หลายคนคงเคยได้ยินคำว่า Image Processing กับ Computer Vision แล้วอาจสงสัยว่าสองอย่างนี้เหมือนกันไหม หรือใช้แทนกันได้รึเปล่า? บทความนี้อยากชวนคุณมาทำความเข้าใจสองศาสตร์นี้ให้ชัดเจนขึ้นและเชื่อมโยงกับสิ่งที่เราเจอในชีวิตประจำวัน
Image Processing เมื่อภาพต้องผ่านกระบวนการปรับปรุงให้สมบูรณ์ยิ่งขึ้น

ภาพที่ 1 ภาพต้นฉบับที่มีสัญญาณรบกวน (ซ้าย) และภาพหลังการประมวลผลด้วย Median filter (ขวา)
(ที่มา: Verma, D., Singh, R., & Satsangi, P. S. (2017). A survey on image processing in noisy environment by fuzzy logic, image fusion, neural network, and non-local means. International Journal of Advanced Research in Computer and Communication Engineering, 6(2).)
ลองนึกถึงเวลาที่คุณถ่ายรูปในที่แสงน้อย แล้วภาพออกมามืดเกินไป สิ่งแรกที่หลายคนทำก็คือเปิดแอปแต่งภาพ ปรับแสง เพิ่มความคม นี่แหละคือสิ่งที่เรียกว่า Image Processing หรือ “การประมวลผลภาพ” มันคือการนำภาพที่มีอยู่แล้วมาปรับปรุงให้ดีขึ้น ไม่ว่าจะเป็นการลบจุดรบกวน ปรับคอนทราสต์ หรือทำให้ภาพดูชัดขึ้น จุดสำคัญคือมันยังไม่ได้เข้าใจว่าในภาพนั้นคืออะไร แค่ “ปรับแต่ง” ให้ภาพสวยขึ้นเท่านั้นเอง
เทคนิคพื้นฐานที่นิยมใช้ใน Image Processing ได้แก่
การปรับแสงและสี (Color Adjustment): ใช้สำหรับปรับระดับความสว่าง (brightness), ความเข้มของสี (saturation), และความสมดุลของแสงสี (white balance) เพื่อให้ภาพมีโทนสีที่สวยงามและเป็นธรรมชาติยิ่งขึ้น
การลบสัญญาณรบกวน (Noise Reduction): ภาพจากกล้องมักมีสัญญาณรบกวน (noise) โดยเฉพาะในสภาวะแสงน้อย เทคนิคนี้ช่วยกรองสิ่งรบกวนออกเพื่อทำให้ภาพดูสะอาดและเรียบร้อยมากขึ้น เช่น Gaussian filter หรือ Median filter ดังภาพที่ 1
การปรับขนาดภาพ (Image Resizing): เพื่อให้เหมาะสมกับการใช้งาน เช่น การลดขนาดภาพสำหรับเว็บไซต์ หรือเพิ่มขนาดภาพสำหรับการพิมพ์ โดยพยายามรักษารายละเอียดให้สูญเสียน้อยที่สุด
การเพิ่มความคมชัด (Sharpening): ช่วยเน้นขอบของวัตถุในภาพให้ชัดเจนขึ้น ด้วยการใช้ฟิลเตอร์ที่ขับให้ลวดลายหรือขอบในภาพโดดเด่นขึ้น เช่น Unsharp Mask หรือ Laplacian filter
Computer Vision เมื่อคอมพิวเตอร์เริ่ม “เข้าใจ” ภาพ
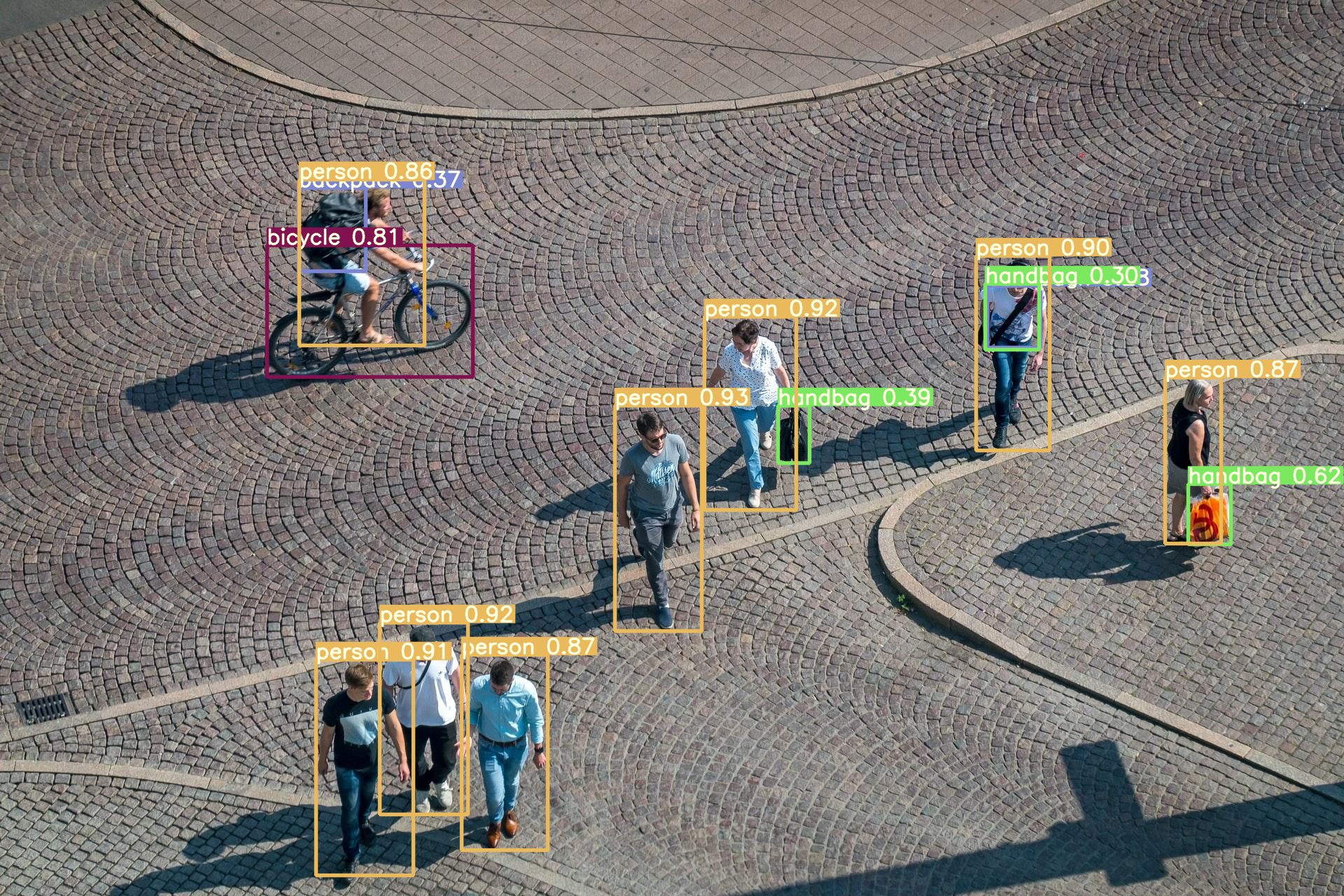
ภาพที่ 2 การตรวจจับวัตถุและใส่คำอธิบายประกอบด้วย Bounding Box
(ที่มา: https://viso.ai/deep-learning/yolov7-guide/)
ถ้า Image Processing เปรียบเหมือนการแต่งภาพให้สวยขึ้น Computer Vision ก็คือการทำให้คอมพิวเตอร์ "เข้าใจ" ว่าในภาพนั้นมีอะไรบ้าง เช่น นี่คือใบหน้าคน นั่นคือลูกบอล หรือภาพนี้คือแมวไม่ใช่หมา ความพิเศษคือมันไม่ได้ดูแค่สีหรือความชัด แต่มองเข้าไปถึงความหมายของภาพเลยทีเดียว
เบื้องหลังความสามารถนี้คือการใช้ AI และ Deep Learning ที่คอมพิวเตอร์จะถูกสอนด้วยภาพนับล้าน จนสามารถแยกแยะสิ่งต่างๆ ได้ ตัวอย่างที่เห็นชัดๆ เช่น ระบบสแกนใบหน้าในมือถือ การตรวจจับคนเดินผ่านกล้องวงจรปิด หรือแม้แต่รถยนต์ไร้คนขับที่ต้องรู้ว่ามีไฟแดงอยู่ข้างหน้า เพื่อหยุดให้ทันเวลา
ตัวอย่างเทคนิคที่นิยมใช้ใน Computer Vision ได้แก่
การจำแนกวัตถุในภาพ (Image Classification): เทคนิคนี้มีเป้าหมายเพื่อให้คอมพิวเตอร์สามารถตอบคำถามว่า "ในภาพนี้มีอะไร?" เช่น จำแนกว่าภาพที่ป้อนเข้ามาคือแมว หรือสุนัข หรือรถยนต์ โดยอาศัยโมเดลเรียนรู้จากข้อมูลภาพจำนวนมาก ตัวอย่างโมเดลที่นิยม เช่น ResNet, EfficientNet, หรือ Vision Transformer (ViT)
การตรวจจับวัตถุ (Object Detection): ต่างจากการจำแนกวัตถุทั่วไป เทคนิคนี้สามารถระบุได้ทั้งว่า มีอะไรอยู่ในภาพ และ ตำแหน่ง ของวัตถุนั้น ๆ ด้วย เช่น การตรวจจับคนหลายคนในภาพเดียว พร้อมทั้งใส่กรอบรอบวัตถุ (bounding box) ดังภาพที่ 2 ตัวอย่างโมเดลที่ใช้ เช่น YOLO, SSD, หรือ Faster R-CNN
การจดจำใบหน้า (Facial Recognition): ใช้สำหรับระบุตัวบุคคลจากใบหน้า โดยเปรียบเทียบใบหน้าที่เห็นกับฐานข้อมูลใบหน้าที่รู้จักแล้ว ปัจจุบันเทคโนโลยีนี้ถูกใช้อย่างแพร่หลายในระบบรักษาความปลอดภัย การควบคุมการเข้าออก หรือแม้แต่การวิเคราะห์พฤติกรรมผู้บริโภคในร้านค้า
การวิเคราะห์การเคลื่อนไหว (Motion Analysis): เป็นการวิเคราะห์การเปลี่ยนแปลงของตำแหน่งวัตถุในวิดีโอ เช่น การติดตามการเคลื่อนไหวของรถยนต์ในระบบกล้องจราจร หรือการประเมินท่าทางของผู้เล่นกีฬาในสนาม เทคนิคพื้นฐานที่ใช้ได้แก่ Optical Flow, Background Subtraction และการ Tracking ด้วย Deep Learning เช่น Deep SORT
สองศาสตร์ที่ต่างกัน แต่ก็ต้องพึ่งกัน
แม้ว่า Image Processing และ Computer Vision จะดูเหมือนเดินคนละเส้นทาง แต่อันที่จริงแล้วมันจับมือกันทำงานอยู่เสมอ ภาพที่ต้องเอาไปวิเคราะห์ด้วย Computer Vision ก็ต้องผ่านการปรับแต่งให้ชัดเจนก่อนจาก Image Processing เพื่อให้การวิเคราะห์แม่นยำขึ้น
ตัวอย่างง่ายๆ คือกล้องในรถยนต์ไร้คนขับ ภาพจากกล้องต้องถูกปรับแสง ลบจุดรบกวนก่อน (Image Processing) จากนั้นระบบถึงจะเอาภาพไปวิเคราะห์ว่ามีคนเดินตัดหน้าหรือไม่ (Computer Vision) สองศาสตร์นี้จึงเหมือนคู่หูที่ต้องทำงานร่วมกันเสมอ
แล้วเราจะเอาไปใช้ยังไงดี?
พอเข้าใจแล้วว่า Image Processing ช่วยให้ภาพดูดีขึ้น ส่วน Computer Vision ช่วยให้คอมพิวเตอร์เข้าใจภาพ เราก็สามารถเลือกใช้ให้ตรงจุดมากขึ้น เช่น งานในวงการแพทย์ก็อาจใช้ Image Processing เพื่อให้ภาพเอ็กซ์เรย์ชัด แล้วใช้ Computer Vision วิเคราะห์ว่าเซลล์แบบไหนน่าจะผิดปกติ หรือในฟาร์มอัจฉริยะ ก็ใช้กล้องถ่ายภาพพืช ปรับภาพให้ดูชัด แล้วใช้ AI วิเคราะห์ว่าสภาพใบไม้โอเคไหม มีโรคหรือเปล่า
หลังจากรู้จักสองศาสตร์นี้แล้ว คุณคิดว่าในอนาคตเราจะสามารถสอนคอมพิวเตอร์ให้ “เห็น” และ “เข้าใจ” โลกได้เทียบเท่ากับมนุษย์หรือไม่? และถ้าทำได้จริง โลกที่เราอยู่จะเปลี่ยนไปมากแค่ไหนกันนะ?
Reference
Gonzalez, R. C., & Woods, R. E. (2018). Digital Image Processing (4th ed.). Pearson Education.
Szeliski, R. (2022). Computer Vision: Algorithms and Applications (2nd ed.). Springer.
Jain, A. K. (2020). Fundamentals of digital image processing. Journal of Visual Communication and Image Representation, 68, 102731. https://doi.org/10.1016/j.jvcir.2020.102731


